[TOC]
大数据知识体系
1 Apache Hadoop 起源与背景
1.1 什么是大数据?
- 商品推荐
1
2
3
* 大量订单如何存储?
* 大量的订单计算?
- 天气预报
1
2
3
* 大量的天气数据如何存储?
* 大量的天气数据计算?
大数据处理的核心问题:
1
2
3
* 数据的存储 ---> 分布式文件系统 ---> HDFS
* 数据的计算 ---> 分布式计算 ---> MapReduce(Yarn平台)
1.2 数据仓库
-
就是一个数据库,一般只做查询
-
可以是Oracle,或是MySQL数据库
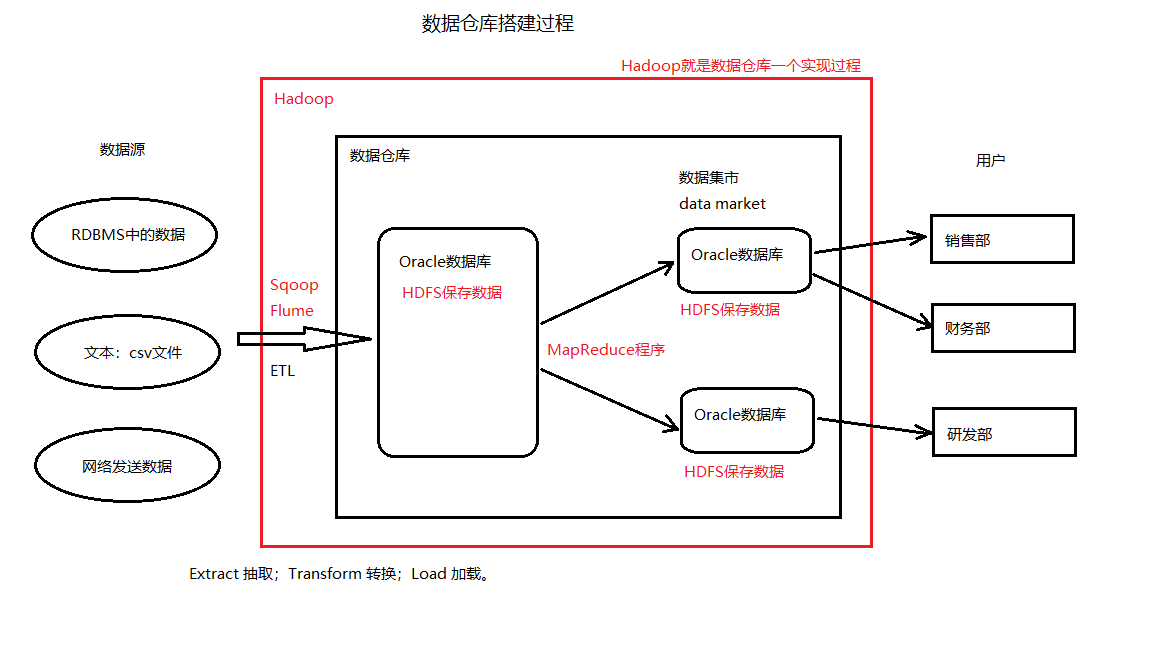
-
Hadoop 就是数据仓库一个实现过程,如上图红色部分
-
数据仓库就是一个OLAP的应用系统
1.3 OLTP 和 OLAP
-
OLTP:Online Transaction Processing 联机事务处理
-
OLAP:Online Analytic Processing 联机分析处理
1.4 Google 的基本思想重要
1.4.1 低成本之道
-
不使用超级计算机,不使用存储(淘宝的去IOE,即去服务器提供商IBM、数据库提供商Oracle、存储设备提供商EMC)
-
大量使用普通的PC服务器(去掉机箱、外设、硬盘),提供有冗余的集群服务
-
全世界多个数据中心,有些附带发电厂
-
运行商向Google付费
1.4.2 三篇论文(Hadoop的思想来源)
(1) GFS(Google File System)
–> HDFS(Hadoop Distributed File System)
-
数据存储
文件元信息:文件保存在硬盘上的位置信息,通过查找文件的元信息,可以知道从哪个硬盘上获得文件。另外,虽然是二进制文件,HDFS提供转换为文本查看的工具。
-
如何找到?
- 索引(Index)
怎么知道索引提高了执行速度?
答:SQL的执行计划(SQL Executation Plan),详见《执行计划及CSV文件数据导入数据库.md》 –> Hive(支持SQL和分区表)
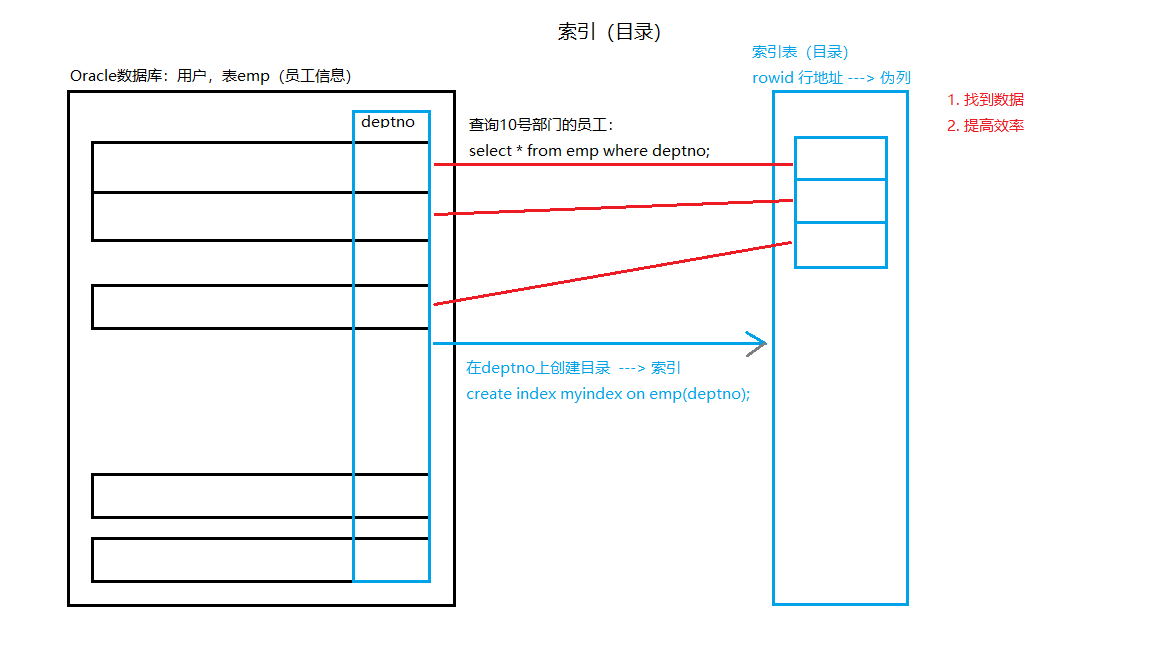
- 倒排索引
解决在HDFS中找到数据的问题。
还可以增加倒排索引的频率:在某个单位资源中出现的频率。

(2) PageRank(搜索排名)
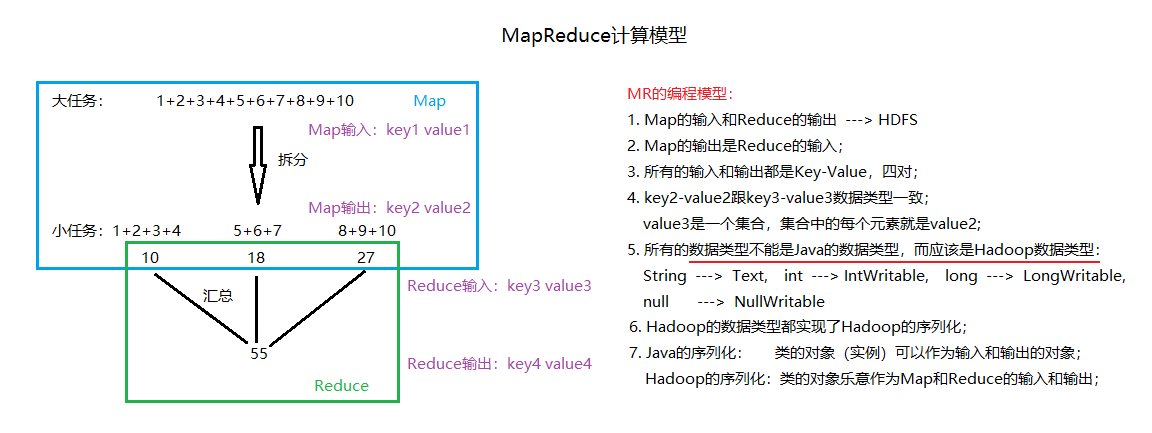
–> MapReduce 计算模型(一个大任务拆分成多个小任务)
网页的引用关系(向量矩阵,可运算出权重高的网页)。
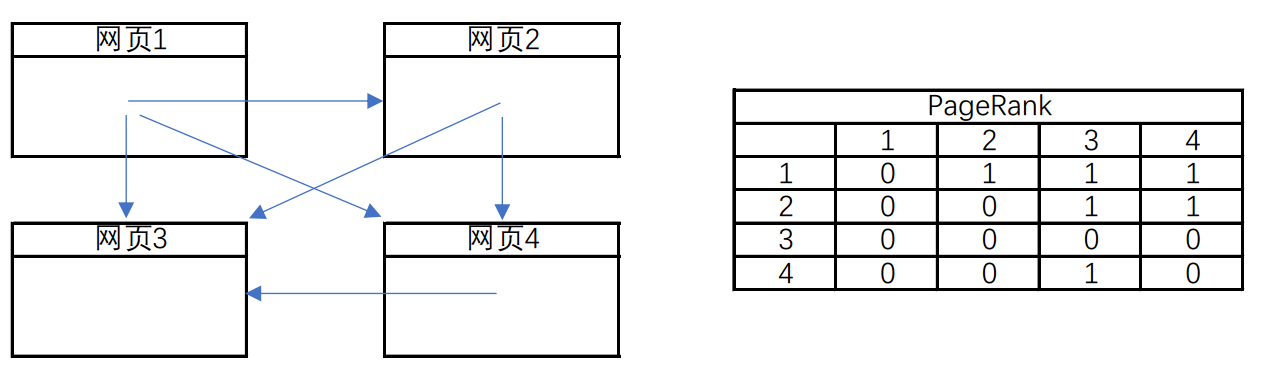
程序分为三部分:Job(主程序), Map(任务拆分), Reduce(任务计算)。编写好程序(*.jar)后,还需要放在Yarn平台执行。
小例子:
Demo: path:/root/training/hadoop-x.x.x/share/hadoop/mapreduce
MR任务:hadoop-mapreduce-examples-x.x.x.jar
统计一个文件中词频(重点介绍):wordcount: A map/reduce program that counts the words in the input files.
$ hadoop jar hadoop-mapreduce-examples-2.4.1.jar wordcount <需要统计词频的文本.txt> <输出目录>
MR的默认排序规则:
数字:升序 字符串:字典顺序 自定义
什么是Java中的序列化?(实现Serializable),Hadoop中的序列化又是什么?
答:如果一个Java类对象实现了序列化,可以作为输入输出的对象。Hadoop的序列化,该类的对象可以作为Map和Reduce的输入输出。
(3) BigTable
–> HBase NoSQL 数据库
HBase是一个分布式的、面向列的开源数据库;BigTable是一个结构化数据的分布式存储系统。
-
关系型数据库:基于
关系模型建立的数据库。关系模型基于二维表(行和列),遵循范式要求。行式数据库:DML(INSERT, UPDATE, DELETE)
-
BigTable完全违背范式的要求,存在数据的冗余,把数据存在一张表中,面向列,好处:提高了查询性能。
列式数据库:SELECT
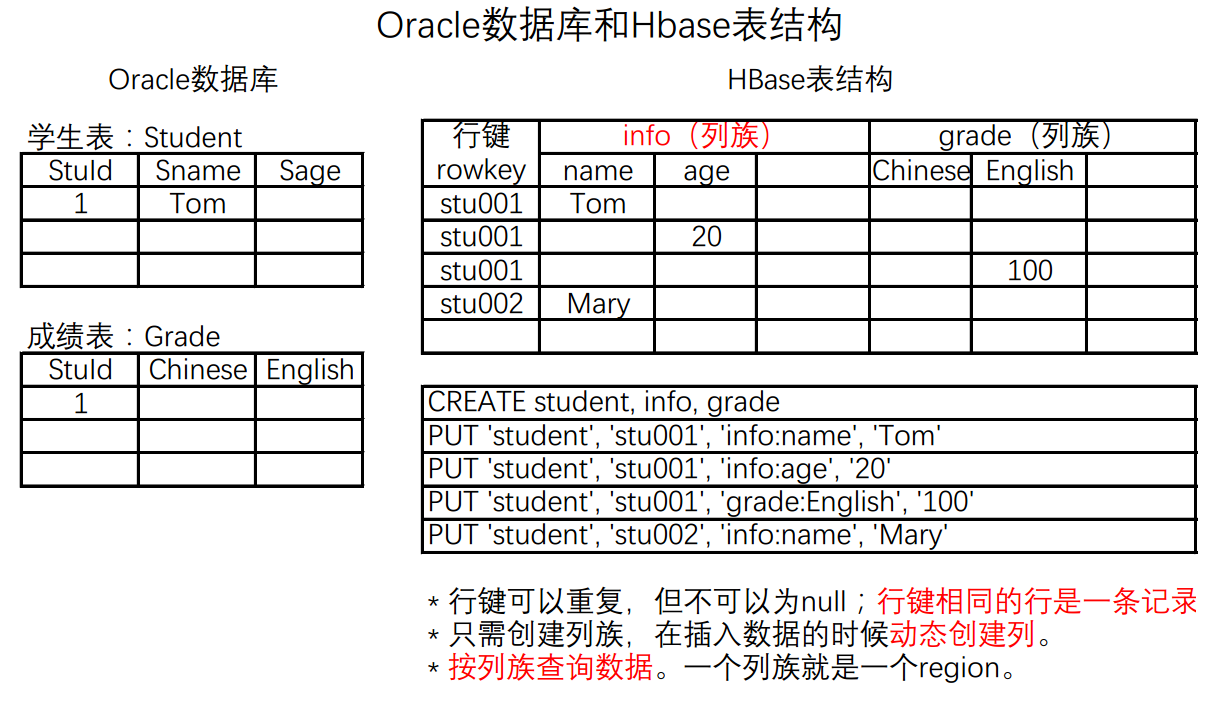
空间浪费?
这里所说的空间浪费,不是如上图中“HBase表结构”所示的空格部分,而是数据冗余造成的空间浪费,换来的是查询性能的提升。
-
NoSQL数据库:基于key-value
常见的NoSQL数据库:
-
Redis:内存数据库
-
HBase:基于Hadoop(HDFS)的列式数据库
-
Cassandra:类似HBase,面向列;(与HBase不同,不常用)
-
MongoDB:文档型的。
思考:设计一个数据库表结构,保存电影信息(大致有电影基本信息、影评、评论)。
-
2 Hadoop 2.X的安装与配置
2.1 安装和配置Hadoop
2.1.1 准备工作
-
设置好网卡IP和网关地址
1 2 3 4 5 6
# 设置网卡IP和网关(临时) $ ifconfig eth0 192.168.253.111 netmask 255.255.255.0 broadcast 192.168.253.255 # 设置网卡IP和网关(永久) $ vi /etc/sysconfig/network-scripts/ifcfg-eth0 $ service network restart
-
安装Linux和JDK
环境变量的设置,修改
~/.bash_profile文件,然后使之生效:1 2 3 4 5 6 7 8 9 10
$ vi ~/.bash_profile # 加入如下内容 JAVA_HOME=/root/training/jdk1.7.0_79 export JAVA_HOME PATH=$JAVA_HOME/bin:$PATH export PATH # 使文件生效 $ source ~/.bash_profile
-
设置主机名和IP对应关系(
/etc/hosts文件中加入hostname和IP的映射关系)1
192.168.253.111 hadoop111
-
关闭防火墙(实验)
1 2
$ service iptables start $ service iptables stop
2.1.2 Hadoop目录结构分析
-
解压hadoop-2.7.5.tar.gz。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
$ tar -zxvf ~/tools/hadoop-2.7.5.tar.gz -C ~/training/ hadoop-2.7.5/ ├── bin # Hadoop 操作命令 ├── etc │ └── hadoop # Hadoop 的所有配置文件 ├── include ├── lib │ └── native ├── libexec ├── sbin # Hadoop的集群管理命令,如启动、停止 └── share ├── doc # 文档 └── hadoop # 按照模块划分的Hadoop各个组件 ├── common # 公共的JAR包 ├── hdfs ├── httpfs ├── kms ├── mapreduce # 有一些MapReduce的例子 ├── tools └── yarn
-
设置环境变量,将
bin和sbin目录加入PATH。1 2 3 4 5 6 7 8 9 10
$ vi ~/.bash_profile # 加入如下内容 HADOOP_HOME=/root/training/hadoop-2.7.5 export HADOOP_HOME PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH export PATH # 使文件生效 $ source ~/.bash_profile
2.1.3 安装模式
1 本地模式
- 特点
- 不具备HDFS的功能,所有数据存在Linux上
- 只能测试MapReduce程序
- 配置
参数文件(目录<hadoop directory>/etc/hadoop) |
配置参数 | 参考值 |
|---|---|---|
| hadoop-env.sh | JAVA_HOME | /root/training/jdk1.7.0_79 |
-
例子
在
~/data/input/data.txt文件中写入如下内容:1 2 3
I love Beijing I love China Beijing is the capital of China
然后执行如下命令:
1
$ hadoop jar /root/training/hadoop-2.7.5/hadoop-mapreduce-examples-2.7.5.jar wordcount /root/data/input/data.txt /root/data/output/wc1
2 伪分布模式
- 特点
- 具备Hadoop的所有功能:HDFS和Yarn
- 在单机上模拟分布式环境
- 开发和测试
-
配置
注:该部分表格用 HTML 编写,在这里无法正常显示,已暂时删除。
-
例子
(1) 在hdfs-site.xml中
<configuration>模块写入如下内容:1 2 3 4 5 6 7 8 9 10 11 12
<!-- 数据库的冗余度,默认为3;伪分布式下建议为1。 --> <!-- 一般跟数据节点(DataNode)个数一致,最大不超过3 --> <property> <name>dfs.replication</name> <value>1</value> </property> <!-- 权限检查,默认为true;暂时不改。 --> <property> <name>dfs.permissions</name> <value>true</value> </property>
(2) 在core-site.xml中写入如下内容:
1 2 3 4 5 6 7 8 9 10 11 12 13
<!-- NameNode地址 --> <!-- 9000是RPC通信端口号 --> <property> <name>fs.defaultFS</name> <value>hdfs://192.168.253.111:9000</value> </property> <!-- HDFS数据、日志和元信息的保存目录,该目录必须先存在! --> <!-- 默认值为 Linux 的 /tmp 目录,系统重新启动,数据会丢失。 --> <property> <name>hadoop.tmp.dir</name> <value>/root/training/hadoop-2.7.5/tmp</value> </property>
(3) 在mapred-site.xml中写入如下内容:
1 2 3 4 5
<!-- 指定MapReduce运行的平台(框架) --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
(4) 在yarn-site.xml中写入如下内容:
1 2 3 4 5 6 7 8 9 10 11
<!-- Yarn 的主节点 --> <property> <name>yarn.resourcemanager.hostname</name> <value>192.168.253.111</value> </property> <!-- MapReduce 处理数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
(5) 对HDFS格式化
1
$ hdfs namenode -format
查看命令执行输出的日志,出现如下日志信息,才是成功的:
1
INFO common.Storage: Storage directory /root/training/hadoop-2.7.5/tmp/dfs/name has been successfully formatted.
(6) 启动Hadoop集群
1 2 3
$ ./training/hadoop-2.7.5/sbin/start-all.sh $ start-dfs.sh $ start-yarn.sh
3 全分布模式(3台及以上)
2.2 配置免密码登录
2.2.1 原理
-
不对称加密:公钥和私钥
公钥:可以公开,用来加密。
私钥:私有,解密。
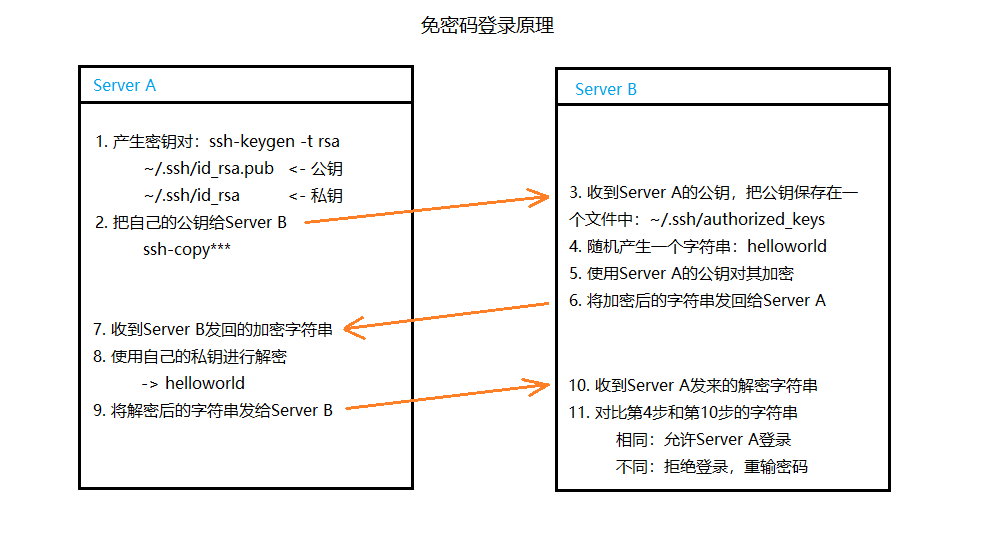
2.2.2 配置
-
产生密钥对
1 2 3 4 5
$ ssh-keygen -t rsa # 出现如下信息表示成功 Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub.
-
发送公钥
1 2
$ ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.253.111 # 该命令会在~/.ssh目录下的authorized_keys文件中以 [加密算法] [密钥串] [发送者] 的格式存放密钥。
3 Hadoop 的体系结构(重要)
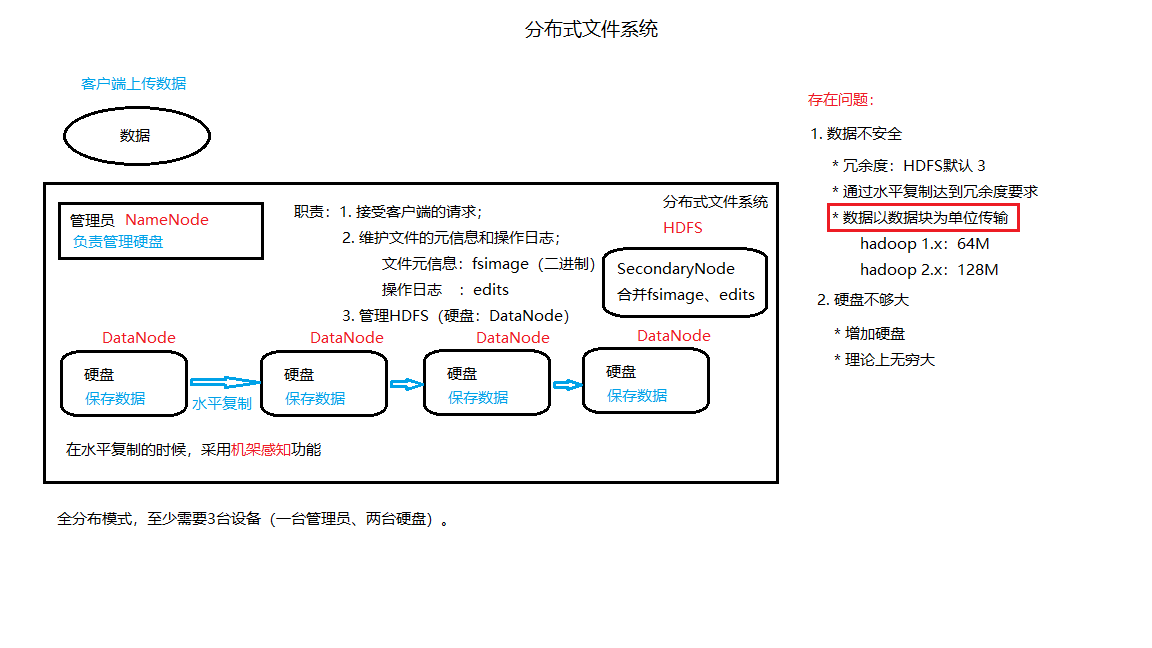
3.1 HDFS:保存数据,主从结构
3.1.1 主节点:NameNode
-
HDFS的管理员
-
职责
-
维护文件的元信息(fsimage文件,二进制)
-
文件的元信息位置:/root/training/hadoop-2.7.5/tmp/dfs/name/current/fsimage_***
-
查看工具:image viewer 转换成一个文本文件
1 2
$ hdfs oiv -i fsimage_0000000000000000076 -o ~/a.xml -p XML $ hdfs oiv -i fsimage_0000000000000000076 -o ~/a.txt
注意点:
当执行MR任务时,Hadoop会把该任务保存到HDFS上(可以在fsimage文件中看到)。
-
fsimage文件
不体现HDFS的最新状态(重要) -
为了提高效率,NameNode会在内存中默认缓存1000M的元信息
1 2 3 4 5
# ~/training/hadoop-2.7.5/etc/hadoop/hadoop-env.sh 文件中进行配置 # The maximum amount of heap to use, in MB. Default is 1000. #export HADOOP_HEAPSIZE= #export HADOOP_NAMENODE_INIT_HEAPSIZE=""
-
-
维护操作日志(edits文件)
-
体现HDFS的最新状态
-
操作日志位置:/root/training/hadoop-2.7.5/tmp/dfs/name/current/edits_***
当前操作的日志文件:edits_inprogress_0000000000000000079
-
查看工具:edits viewer,
只能是XML1
$ hdfs dfs oev edits_inprogress_0000000000000000079 -o ~/b.xml
-
-
3.1.2 从节点:DataNode
-
职责
按数据块保存数据。
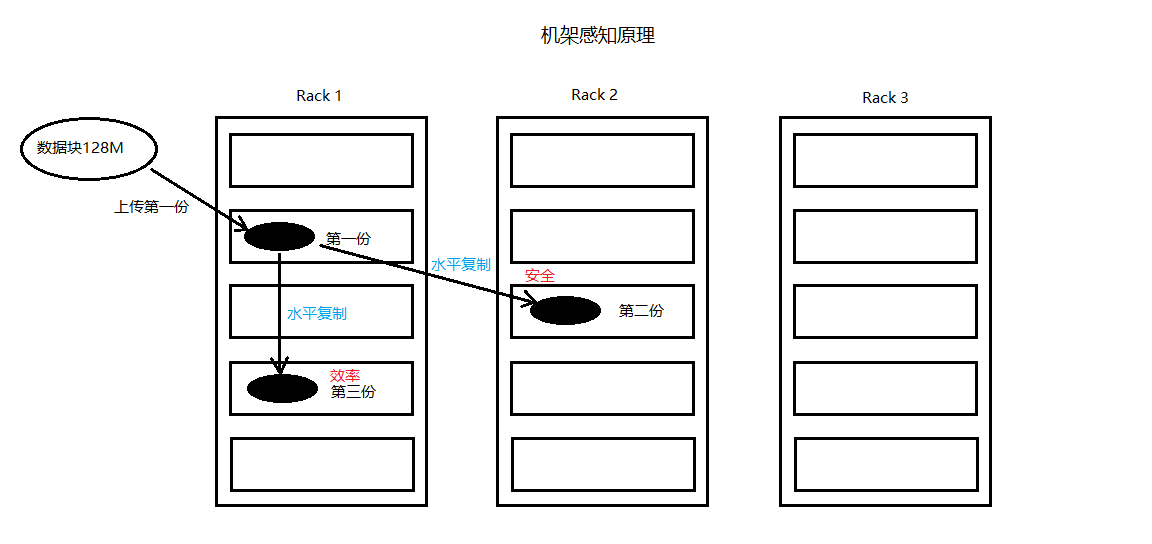
Hadoop 1.x:64M
Hadoop 2.x:128M
-
数量
伪分布模式:只有一个
全分布模式:至少两个
-
保存位置及文件分析
-
路径
/root/training/hadoop-2.7.5/tmp/dfs/data/current/BP-1601732374-192.168.35.111-1528631364073/current/finalized/subdir0/subdir0/
-
文件的类型:
- blk_1073741826:数据库文件
- blk_1073741826_1002.meta:记录数据块保存信息
-
通过
水平复制达到数据冗余度的要求 -
机架感知
-
hdfs balancer:当有新的DataNode加入时,数据的存放会不均匀,可以手动调整。
-
3.1.3 SecondaryNode
-
职责
对fsimage文件和edits日志文件定期进行合并。
-
默认跟NameNode在同一个机架上,提高合并的效率
-
位置
/root/training/hadoop-2.7.5/tmp/dfs/namesecondary/current
-
日志合并过程
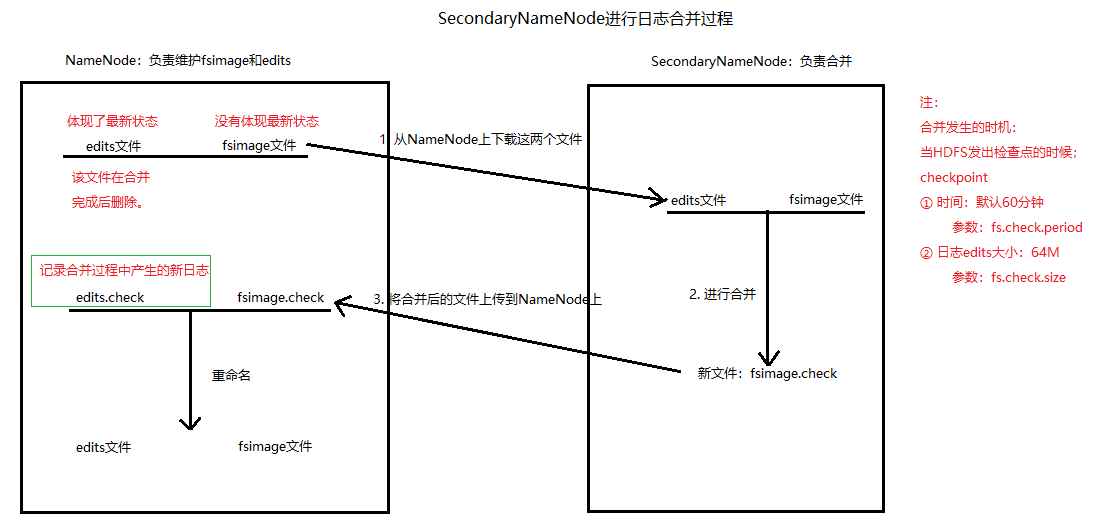
配置文件:hadoop-2.7.5/etc/hadoop/hdfs-site.xml
修改参数:fs.check.period,fs.check.size
3.1.4 适合处理怎样的文件
-
文件(目录)元信息的大概150字节
-
Hadoop适合处理
单个的大文件(数量小),内容大的数据如果数据的文件数量过多,需要记录的元信息就会很多,效率会降低,因此处理数据前需要先合并数据。
3.2 Yarn平台(容器)
运行MapReduce程序(Java程序)
主从结构
-
主节点:ResourceManager
-
从节点:NodeManager
4 Hadoop应用案例分析
-
基于Hadoop的企业级架构
-
使用HBase(Hadoop)分析日志
-
Hadoop在淘宝的应用
5 HDFS
Hadoop Distributed File System(Hadoop分布式文件系统) –> 数据的存储
5.1 Web Console
管理员NameNode:http://192.168.253.111:50070
SecondaryNameNode网页:监控日志的合并信息,http://192.168.253.111:50090
若访问不了,请检查防火墙,最好先关闭防火墙。
-
NameNode infomation Summary
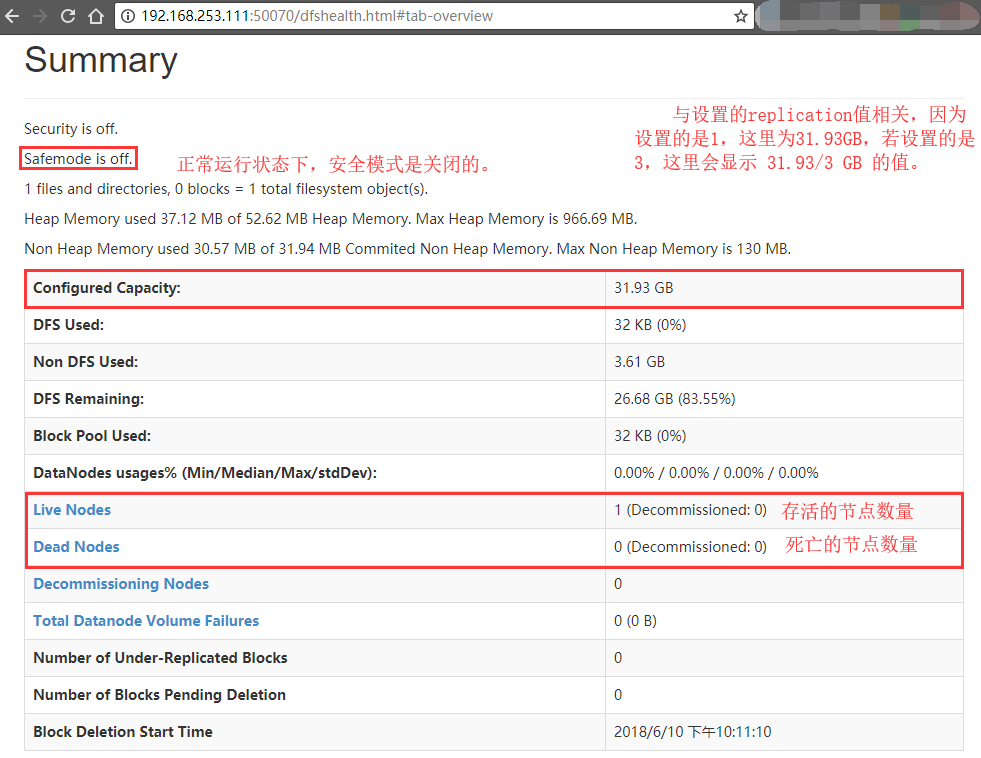
-
日志和元信息的保存
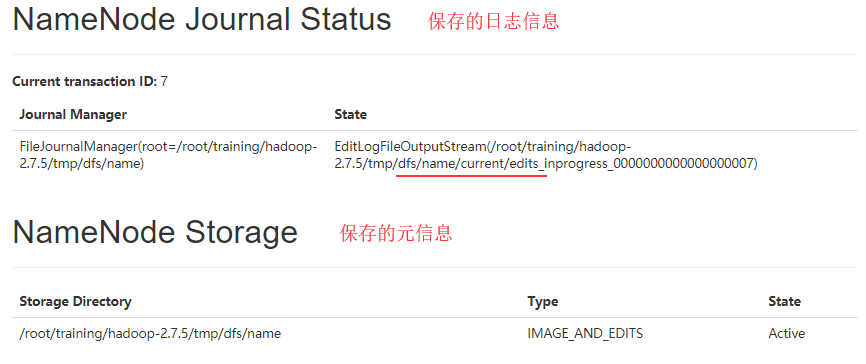
-
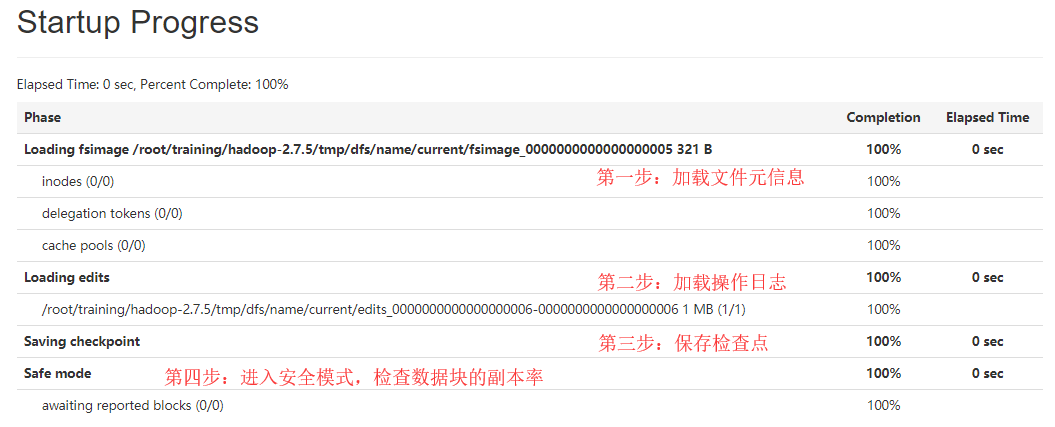
Startup Progress
5.2 命令行
5.2.1 操作命令
!!!区分大小写
-
常用命令
命令 说明 示例 -mkdir 在HDFS上创建目录(不能级联创建) hdfs dfs -mkdir /data -ls 列出hdfs文件系统根目录下的目录和文件 hdfs dfs -ls / -ls -R
-lsr列出hdfs文件系统所有的目录和文件 hdfs dfs -R / -put 上传文件或从键盘输入字符到hdfs。
注意:Hadoop 2.X会对大于128M的文件分块上传和存储hdfs dfs -put data.txt /data/input -moveFromLocal 与put相类似,命令执行后源文件local src被删除,也可以从键盘读取输入到hdfs file 中。 hdfs dfs -moveFromLocal data.txt /data/input -copyFromLocal 与put相类似,也可以从键盘读取输入到hdfs file中。 hdfs dfs -copyFromLocal data.txt /data/input -copyToLocal -get 将HDFS中的文件复制到本地系统中。 hdfs dfs -get /data/inputdata.txt /root/ -rm
-rmr每次可以删除多个文件或目录 hdfs dfs -rm <hdfs file>
hdfs dfs -rm -r <hdfs dir>-getmerge 将hdfs指定目录下所有文件排序后合并到local指定的文件中,文件不存在时会自动创建,文件存在时会覆盖里面的内容 hdfs dfs -getmerge /data/input /root/a.txt -cp 拷贝hdfs上的文件 -mv 移动hdfs上的文件 -count 统计hdfs对应路径下的目录个数,文件个数,文件总计大小,显示为目录个数、文件个数、文件总计大小、输入路径 -du 显示hdfs对应路径下每个文件夹和文件的大小 -text、-cat 将文本文件或某些格式的给文本文件通过文本格式输出 balancer 如果管理员发现某些DataNode保存数据过多,某些DataNode保存数据相对较少,可以使用上述命令手动启动内部的均衡过程。 -
dfs的路径和目录结构

-
上传文件
1
$ hdfs dfs -put data/input/data.txt /data
上传data.txt(60B)文件后,可以看到该文件实际占用60B空间,但数据块大小为128M。
-
删除文件
1 2 3 4
$ hdfs dfs -rmr /data/data.txt # 返回信息 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes. Deleted /data/data.txt
如果启用回收站,日志信息?回收站的本质是?
解析见5.7
-
上传多个文件并合并下载
1 2 3 4 5 6 7 8
$ vi student01.txt student02.txt student03.txt # 第一个文件两行数据:1, Tom, 23; 2, Mary, 24 # 第二个文件一行数据:3, Mike, 19 # 第三个文件一行数据:4, Jone, 22 $ hdfs dfs -mkdir /students $ hdfs dfs -put ./data/student0* /students $ hdfs dfs -getmerge /students students.txt
-
数据均衡(对伪分布意义不大)
1
$ hdfs balancer
5.2.2 管理命令
-
常用命令
HDFS管理命令帮助信息:hdfs dfsadmin
命令 说明 示例 -report 显示文件系统的基本数据 hdfs dfsadmin -report -safemode HDFS的安全模式命令
<enter | leave | get | wait>hdfs dfsadmin -safemode enter|leave|get|wait 安全模式下,只读;不能创建目录等操作。
5.2.3 其他操作命令
-
权限管理
1
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
-
快照创建、删除、重命名
1 2 3
[-createSnapshot <snapshotDir> [<snapshotName>]] [-deleteSnapshot <snapshotDir> <snapshotName>] [-renameSnapshot <snapshotDir> <oldName> <newName>]
-
清空HDFS回收站
1
[-expunge]
5.2.4 其他管理命令
-
快照的开启和禁用
1 2
[-allowSnapshot <snapshotDir>] [-disallowSnapshot <snapshotDir>]
-
设置HDFS的配额(Quota)
1 2 3 4
[-setQuota <quota> <dirname>...<dirname>] [-clrQuota <dirname>...<dirname>] [-setSpaceQuota <quota> [-storageType <storagetype>] <dirname>...<dirname>] [-clrSpaceQuota [-storageType <storagetype>] <dirname>...<dirname>]
5.3 Java API
需要包含的JAR包:
1
2
3
4
hadoop-2.7.5/share/hadoop/common/*.jar
hadoop-2.7.5/share/hadoop/common/lib/*.jar
hadoop-2.7.5/share/hadoop/hdfs/*.jar
hadoop-2.7.5/share/hadoop/hdfs/lib/*.jar
5.3.1 创建目录
-
目标:
hdfs dfs -mkdir /tools权限问题?
-
Java程序
1 2 3 4 5 6 7 8 9 10 11 12 13
public class MakeDirDemo { @Test public void test1() throws IOException { System.setProperty("HADOOP_USER_NAME", "root"); // 配置信息:NameNode的地址 Configuration configuration = new Configuration(); configuration.set("fs.defaultFS", "hdfs://192.168.253.111:9000"); // 创建一个HDFS客户端 FileSystem fileSystem = FileSystem.get(configuration); // 创建目录 fileSystem.mkdirs(new Path("/mkbyjava")); } }
错误提示:
AccessControlException: Permission denied: user=JY, access=WRITE, inode=”/”:root:supergroup:drwxr-xr-x
问题分析:
要注意权限问题,根目录权限:root:supergroup:drwxr-xr-x;而Java执行程序时,使用本地计算机名(属于其他用户)访问,其他用户没有写权限。
解决方案:
① 由于HDFS对权限检查的功能非常弱(你说你是谁,你就是谁,不会进行身份验证),设置环境变量:”HADOOP_USER_NAME”=”root”
② 使用Java程序的 -D 的参数。java -DHADOOP_USER_NAME=root Demo
③ 修改目录权限:
hdfs dfs chmod 777 /.④ 修改Hadoop配置参数:dfs.permissions=false
5.3.2 上传数据
-
Java IO流的方式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
@Test public void uploadByIO() throws IOException { // 配置NameNode的地址 Configuration configuration = new Configuration(); configuration.set("fs.defaultFS", "hdfs://192.168.253.111:9000"); // 得到HDFS客户端 FileSystem fileSystem = FileSystem.get(configuration); // 创建一个输入流,读取本地文件 InputStream in = new FileInputStream("C:\\Users\\HS\\Desktop\\宅客\\大数据资料\\安装介质\\hadoop-2.7.5.tar.gz"); // 创建一个指向HDFS的输出流 OutputStream out = fileSystem.create(new Path("/mkbyjava/hadoop-2.7.5.tar.gz")); // 创建一个缓冲区 byte[] buffer = new byte[1024]; // 定义变量,代表读入数据的长度 int len = 0; while((len = in.read(buffer)) > 0) { // 从输入流中读取数据并写到输出流 out.write(buffer, 0, len); } // 写到输出流 out.flush(); // 关闭IO out.close(); in.close(); }
-
简单的方式
1 2 3 4 5 6 7 8 9 10 11 12 13 14
@Test public void uploadByUtils() throws IOException { // 配置NameNode的地址 Configuration configuration = new Configuration(); configuration.set("fs.defaultFS", "hdfs://192.168.253.111:9000"); // 得到HDFS客户端 FileSystem fileSystem = FileSystem.get(configuration); // 创建一个输入流,读取本地文件 InputStream in = new FileInputStream("C:\\Users\\HS\\Desktop\\宅客\\大数据资料\\安装介质\\hadoop-2.7.5.tar.gz"); // 创建一个指向HDFS的输出流 OutputStream out = fileSystem.create(new Path("/mkbyjava/hadoop-2.7.5.tar.gz")); // 使用HDFS的工具类,简化上传 IOUtils.copyBytes(in, out, 1024); }
5.3.3 下载数据
-
Java IO流的方式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
@Test public void downloadByIO() throws IOException { // 配置NameNode的地址 Configuration configuration = new Configuration(); configuration.set("fs.defaultFS", "hdfs://192.168.253.111:9000"); // 得到HDFS客户端 FileSystem fileSystem = FileSystem.get(configuration); // 创建一个输出流 OutputStream out = new FileOutputStream("C:\\Users\\HS\\Desktop\\宅客\\大数据资料\\安装介质\\download.hadoop-2.7.5.tar.gz"); // 创建一个读取HDFS的输入流 InputStream in = fileSystem.open(new Path("/mkbyjava/hadoop-2.7.5.tar.gz")); // 创建一个缓冲区 byte[] buffer = new byte[1024]; // 定义变量,代表读入数据的长度 int len = 0; while ((len = in.read(buffer)) > 0) { // 从输入流中读取数据并写到输出流 out.write(buffer, 0, len); } // 写到输出流 out.flush(); // 关闭IO out.close(); in.close(); }
-
简单的方式
1 2 3 4 5 6 7 8 9 10 11 12 13 14
@Test public void downloadByUtils() throws IOException { // 配置NameNode的地址 Configuration configuration = new Configuration(); configuration.set("fs.defaultFS", "hdfs://192.168.253.111:9000"); // 得到HDFS客户端 FileSystem fileSystem = FileSystem.get(configuration); // 创建一个输出流 OutputStream out = new FileOutputStream("C:\\Users\\HS\\Desktop\\宅客\\大数据资料\\安装介质\\download.hadoop-2.7.5.tar.gz"); // 创建一个读取HDFS的输入流 InputStream in = fileSystem.open(new Path("/mkbyjava/hadoop-2.7.5.tar.gz")); // 使用HDFS的工具类,简化上传 IOUtils.copyBytes(in, out, 1024); }
5.3.4 查询
-
查询文件/目录的属性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
@Test public void queryFileProperties() throws IOException { // 设置NameNode的地址 Configuration configuration = new Configuration(); configuration.set("fs.defaultFS", "hdfs://192.168.253.111:9000"); // 得到HDFS的客户端 FileSystem fileSystem = FileSystem.get(configuration); // 获取目录信息 FileStatus[] fileStatus = fileSystem.listStatus(new Path("/mkbyjava")); for(FileStatus fs : fileStatus) { // 获取文件属性 System.out.println(fs.isDirectory()?"目录":"文件"); System.out.println(fs.getBlockSize()); System.out.println(fs.getAccessTime()); } }
-
查询数据块主机和名称信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
@Test public void queryFileLocation() throws IOException { // 设置NameNode的地址 Configuration configuration = new Configuration(); configuration.set("fs.defaultFS", "hdfs://192.168.253.111:9000"); // 得到HDFS的客户端 FileSystem fileSystem = FileSystem.get(configuration); // 获取文件信息 FileStatus fileStatus = fileSystem.getFileStatus(new Path("/mkbyjava/hadoop-2.7.5.tar.gz")); BlockLocation[] blockLocations = fileSystem.getFileBlockLocations(fileStatus, 0, fileStatus.getLen()); for(BlockLocation bl : blockLocations) { // getHosts() 返回数组:一个文件,如果冗余度不是1,就是在不同的机架(服务器)上。 System.out.println(Arrays.toString(bl.getHosts())); // 数据块的名称信息 System.out.println(Arrays.toString(bl.getNames())); } }
上面查询的结果返回了如下信息。
1 2 3 4
[hadoop111] [192.168.253.111:50010] [hadoop111] [192.168.253.111:50010]
因为这个文件大小超过128M,需要两个数据块存放,返回了两个数据块的信息。
5.4 HDFS文件上传过程
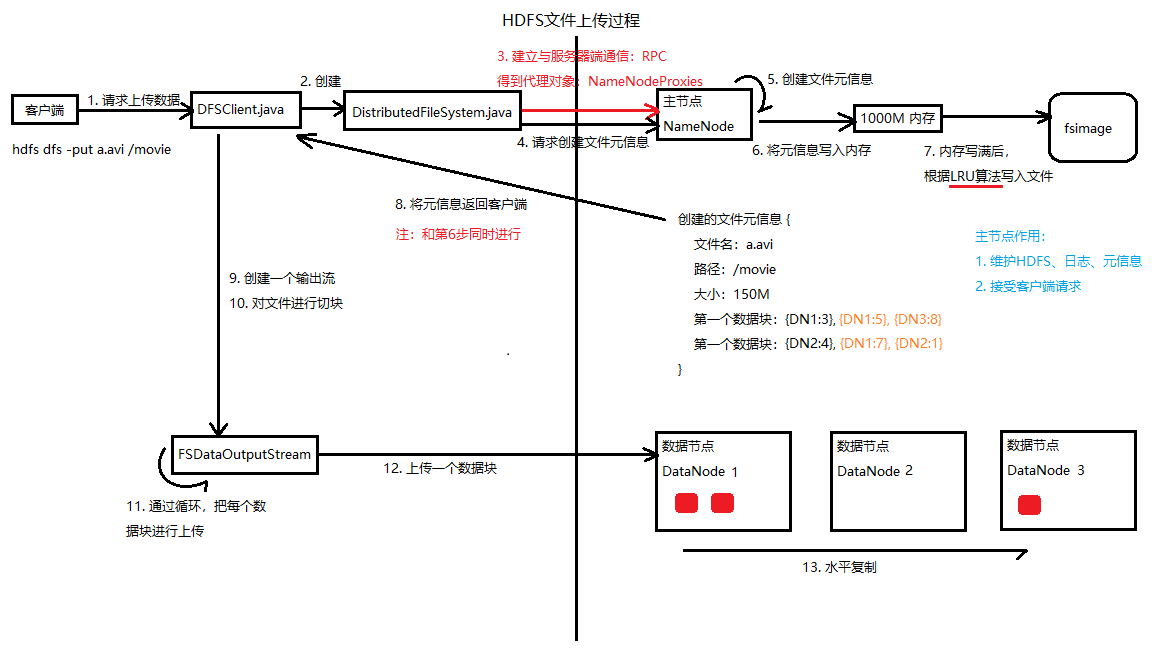
5.5 HDFS文件下载过程
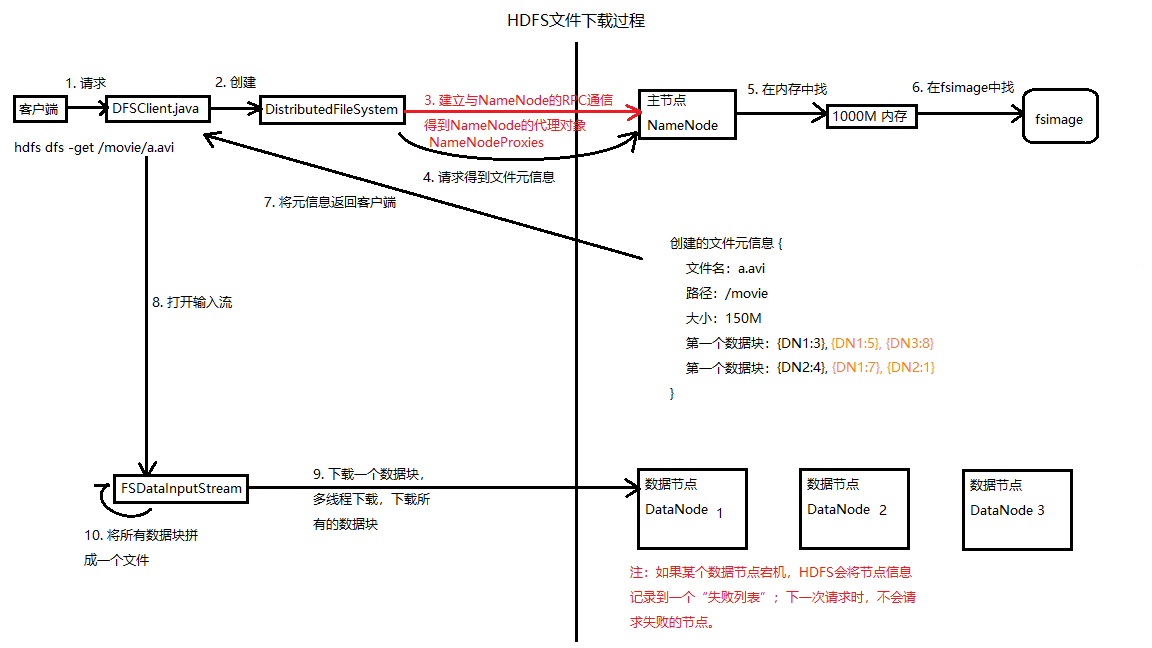
注意点:
一旦客户端从主节点拿到文件的元信息,就直接和数据节点交互。
5.6 主节点NameNode存在的问题
- 性能瓶颈
- 单点故障
5.6.1 LoadBalance:负载均衡
解决方案:NameNode联盟(Federation)思想
思想.png)
5.6.2 Fail Over:失败迁移
解决方案:ZooKeeper实现NameNode的HA(High Avaibility 高可用性)
.png)
注意点:
Hadoop 1.X 不能用上述两个方法解决单点问题。
5.7 高级功能 - 回收站
5.7.1 补充 - Oracle数据库的回收站
删除表:DROP TABLE,放入Oracle数据库回收站,可以闪回(flashback)。
-- 删除emp表
SQL> DROP TABLE emp;
Table dropped.
SQL> SELECT * FROM tab;
-- 这里返回的信息包含删除的表,但是表名发生变化
回收站的基本操作:
-- 通过回收站中的表名查询数据
SELECT * FROM "回收站中的表名";
-- 查询回收站
SHOW RECYCLEBIN;
-- 清空回收站
PURGE RECYCLEBIN;
-- 彻底删除表(不经过回收站)
DROP TABLE emp PURGE;
闪回(flashback,一种不完全恢复),Oracle 11g中有7种类型
-- 闪回删除
SQL> flashback table emp to before drop;
SQL> flashback table "回收站中的名字" to before drop;
-- 闪回同名表,先闪回后删除的表,再闪回先删除的表,需要执行以下语句重命名
SQL> flashbask table emp to before drop rename to em_old;
5.7.2 HDFS 回收站
本质:在某个时间内把删除的数据移动到一个隐藏目录下(回收站)。
默认禁用。
1
2
3
4
$ hdfs dfs -rmr /data/data.txt
# 返回信息
INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes.
Deleted /data/data.txt
如果启用回收站,日志信息?回收站的本质是?
启用回收站的方式:(在core-site.xml中添加fs.trash.interval来打开配置时间阈值)
1
2
3
4
<property>
<name>fs.trash.interval</name>
<value>1440<value><!-- 单位:分钟 -->
</property>
-
回收站里的文件可以快速恢复。
-
设置时间阈值,当回收站里存放文件的时间超过阈值,就被彻底清除,并释放占用的数据块。
-
查看回收站
1
$ hdfs dfs -lsr /usr/root/.Trash/Current
-
从回收站中恢复
1
$ hdfs dfs -cp /usr/root/.Trash/Current/input/data.txt /input
-
清空回收站
1
$ hdfs dfs -expunge
5.8 高级功能 - 配额Quota
5.8.1 名称配额:决定目录下文件的个数
1
2
3
4
5
# 限制testQuota目录下最多只能有2个文件
$ hdfs dfsadmin -setQuota 3 /testQuota
# 清除testQuota目录配额限制
$ hdfs dfsadmin -clrQuota /testQuota
小提示:
如果目录下已有1个文件,可以将Quota设置为1,设置后,之前的文件依然存在。
5.8.2 空间配额:决定目录下文件的大小
1
2
3
4
5
# 限制testQuota目录下最多只能放1M的文件
$ hdfs dfsadmin -setSpaceQuota 1M /testQuota
# 清除testQuota目录配额限制
$ hdfs dfsadmin -clrSpaceQuota /testQuota
注意:
空间配额的大小不能小于数据块的大小(128M),不能是小数。
???空间配额设置为128M,只能上传一个小于128M的文件;设置为129M,可以上传多个文件。
5.9 高级功能 - 快照 Snapshot(备份)
HDFS备份:快照
本质:将要备份的数据拷贝一份到隐藏目录。
默认禁用。
除非数据很重要,一般不开,原因如下:
- HDFS默认数据冗余度:3
- 造成空间浪费
-
防止重要数据的丢失
-
备份
- 备份策略:完全备份、增量备份(相对上一次备份)、差异备份(相对上一次全备份)
- 备份模式:全库备份、部分备份
-
案例:
对/snapshot目录执行快照
1 2 3 4 5 6 7 8 9 10 11 12 13
# 使用管理员开启该目录的快照功能;关闭命令 -disallowSnapshot $ hdfs dfsadmin -allowSnapshot /snapshotdir # 使用hdfs的操作命令执行备份(快照) $ hdfs dfsadmin -createSnapshot /snapshotdir ssd_backup_1 # 查看快照 $ hdfs lsSnapshottableDir # 对比快照 $ dhfs snapshotDiff /snapshotdir ssd_backup_1 ssd_backup_2 # 恢复快照 $ hdfs dfs -cp /snapshotdir/.snapshot/ssd_backup_1/data.txt /snapshotdir
快照位置:/snapshotdir/.snapshot/ssd_backup_1/
补充内容:
Oracle RMAN:Recovery Manager
5.10 高级功能 - 安全模式 SafeMode
-
管理的命令:hdfs dfsadmin -safemode [get enter leave wait ] - 如果HDFS处于安全模式,只读状态。
- 作用:检查数据块的副本率是否满足要求
- 满足,退出安全模式
- 不满足,DataNode就会进行数据块的水平复制,以达到数据冗余度要求
阅读:
当集群启动时,会先进入安全模式。当系统处于安全模式时会检查数据块的完整性,假设我们设置的副本数(即
dfs.replication)是5,那么在DataNode上就应该有5个副本存在,假设只存在3个副本,那么比例就是3/5=0.6,在配置文件hdfs-default.xml中定义了一个最小的副本的副本率0.999,如下:
副本率0.6小于0.999,此时系统会自动复制副本到其他的DataNode。如果系统中有8个副本,多余的副本会被删除。
5.11 高级功能 - 权限(四种方式)
你说你是谁,你就是谁,HDFS不会去验证。
Hadoop本身的权限和访问控制非常弱。
可以借助 Kerberos 安全框架。
5.12 底层原理:RPC和Java动态代理
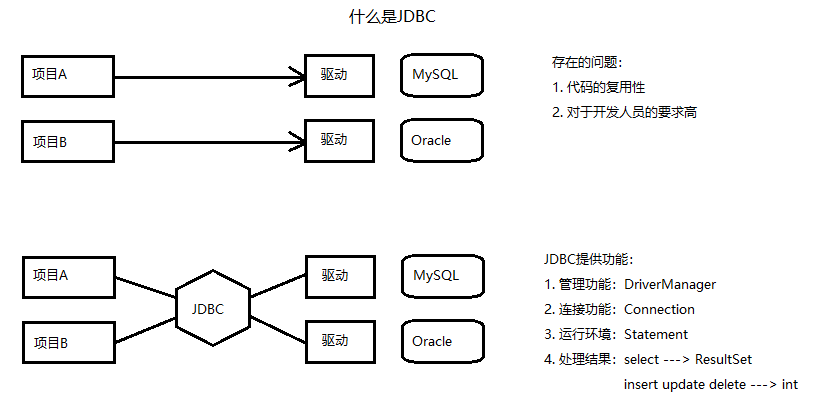
5.12.1 Java动态代理:类名前”$”
- 动态代理是一种包装设计模式:《实用J2EE的设计模式》
- 思想:在不修改源代码的情况下,增强(改变)程序的功能逻辑。

-
案例:实现一个数据库连接池,写JDBC程序
重点:增强(改写)connection.close()方法 -> 将该连接返回给连接池,而不是数据库。
-
MySQL数据库配置
创建一个新的数据库:
create database hive;创建一个新的用户:
create user 'hiveowner'@'%' identified by 'password';给该用户授权:
grant all on hive.* to 'hiveowner'@'%';grant all on hive.* to 'hiveowner'@'localhost' identified by 'password'; -
数据库连接池的实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55
package xyz.jiangjiangy.practice; public class MyDataSource implements DataSource { // 定义数据库属性 private static String driver = "com.mysql.jdbc.Driver"; private static String url = "jdbc:mysql://127.0.0.1:3306/hive"; private static String username = "hiveowner"; private static String password = "passsword"; // 初始化的时候,就放入 10 个连接到连接池中 // 定义链表来作为连接池 private static LinkedList<Connection> pool = new LinkedList<>(); static { try { Class.forName(driver); for (int i = 0; i < 10; i++) { pool.add(DriverManager.getConnection(url, username, password)); } } catch (ClassNotFoundException e) { e.printStackTrace(); } catch (SQLException e) { e.printStackTrace(); } } @Override public Connection getConnection() throws SQLException { // 判断是否存在连接 if (pool.size() > 0) { Connection conn = pool.removeFirst(); Connection proxyConnection = (Connection) Proxy.newProxyInstance(MyDataSource.class.getClassLoader(), conn.getClass().getInterfaces(), new InvocationHandler() { @Override public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { // 对 close 方法感兴趣 if ("close".equals(method.getName())) { // 客户端调用了 close 方法,将连接还给连接池 pool.add(conn); return null; } else { return method.invoke(conn, args); } } }); return proxyConnection; } else { throw new SQLException("无可用连接,请稍后尝试..."); } } // 省略其他未实现的方法 }
-
5.12.2 RPC(Remote Procedure Call)
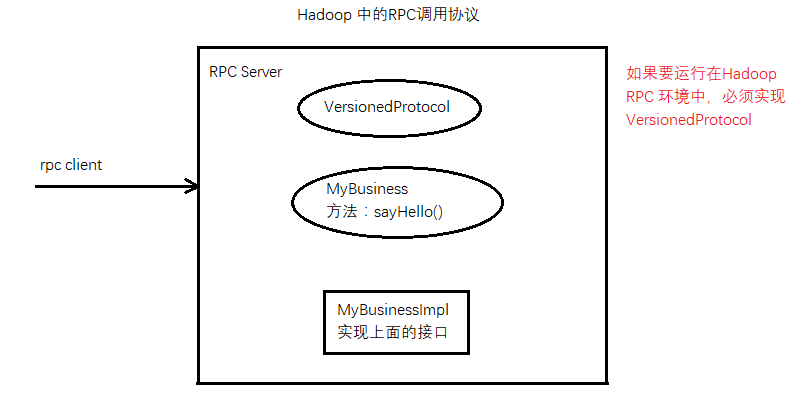
-
Server 端实现
-
MyBusiness 接口类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
package rpc.server; import org.apache.hadoop.ipc.VersionedProtocol; /** * @author jiangydev. * @date 2018/9/17. */ public interface MyBusiness extends VersionedProtocol { /** * 定义自己的签名 ID,通过这个 ID 号,就能区分在客户端调用的时候,调用的是哪个具体的实现 * 变量名字必须为 versionID * 使用该 versionID 构造签名 */ public static long versionID = 1L; String sayHello(String name); }
-
MyBusinessImpl 实现类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
package rpc.server; import org.apache.hadoop.ipc.ProtocolSignature; import java.io.IOException; /** * @author jiangydev. * @date 2018/9/17. */ public class MyBusinessImpl implements MyBusiness { @Override public String sayHello(String name) { return "hello " + name; } @Override public long getProtocolVersion(String s, long l) throws IOException { // 返回ID return MyBusiness.versionID; } @Override public ProtocolSignature getProtocolSignature(String s, long l, int i) throws IOException { // 通过 versionID 构造签名 return new ProtocolSignature(MyBusiness.versionID, null); } }
-
Server 测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
package rpc.server; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.ipc.RPC; import java.io.IOException; /** * @author jiangydev. * @date 2018/9/17. */ public class MyRPCServer { public static void main(String[] args) throws IOException { // Hadoop 的 RPC 框架发布我们的程序 RPC.Builder builder = new RPC.Builder(new Configuration()); builder.setBindAddress("127.0.0.1") .setPort(7788) .setProtocol(MyBusiness.class) // 发布的接口 .setInstance(new MyBusinessImpl()); // 接口的实现类 // 创建一个 RPC Server RPC.Server server = builder.build(); server.start(); } }
-
-
Client 端实现
-
Client 端测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
package rpc.client; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.ipc.RPC; import rpc.server.MyBusiness; import java.io.IOException; import java.net.InetSocketAddress; /** * @author jiangydev. * @date 2018/9/17. */ public class MyRPCClient { public static void main(String[] args) throws IOException { // 通过 RPC 协议获得服务器端一个句柄 --> 得到一个代理对象 // RPC.getProxy(Class<rpc.server.MyBusiness> protocol, 调用的接口 // long clientVersion, 签名的ID号 // InetSocketAddress addr, RPC Server 的地址 // Configuration conf); 配置信息 MyBusiness proxy = RPC.getProxy(MyBusiness.class, MyBusiness.versionID, new InetSocketAddress("localhost", 7788), new Configuration()); // 调用服务器端功能 System.out.println(proxy.sayHello("jiangydev")); } }
-
6 MapReduce
MRUnit:MapReduce(离线计算框架)
计算模型(Java 程序)
6.1 WordCount 分析数据的流动过程

6.2 第一个 MapReduce 程序: WordCount
6.2.1 WordCountMapper
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
package wordcount;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @author jiangydev.
*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
@Override
protected void map(LongWritable key1, Text value1, Context context) throws IOException, InterruptedException {
/**
* Context Map 阶段的上下文
* 上文:HDFS 输入
* 下文:Reducer
*/
// 得到数据
String str = value1.toString();
// 按照空格进行分词
String[] words = str.split(" ");
// 将每个单词的频率输出到 reducer: k2, v2
for (String w : words) {
context.write(new Text(w), new LongWritable(1));
}
}
}
6.2.2 WordCountReducer
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
package wordcount;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @author jiangydev.
*/
public class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text key3, Iterable<LongWritable> values3, Context context) throws IOException, InterruptedException {
/**
* 上文:Map
* 下文:HDFS
*/
// 求和
long total = 0;
for (LongWritable value2 : values3) {
total = total + value2.get();
}
// 输出
context.write(key3, new LongWritable(total));
}
}
6.2.3 WordCountMain
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
package wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @author jiangydev.
*/
public class WordCountMain {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 入口:由 Hadoop 框架 Yarn 平台调用
// 创建一个任务
Job job = Job.getInstance(new Configuration());
job.setJarByClass(WordCountMain.class);
// 指定任务的map
job.setMapperClass(WordCountMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 指定任务的reducer
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 指定任务的输入和输出
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 提交执行任务
job.waitForCompletion(true);
}
}
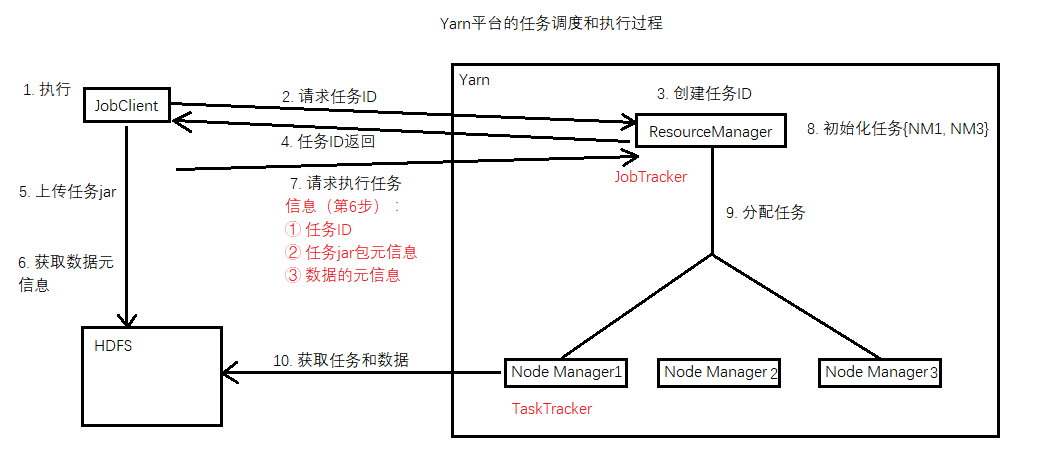
6.3 Yarn 平台的任务调度和执行过程
6.3 MR的高级功能
- 排序
- 分区 Partition
- 序列化
- 合并 Combiner
6.4 MR的核心 - Shuffle 洗牌
6.5 案例
- 使用MRUnit进行单元测试
- 数据去重 select distinct
- 多表查询
- 自连接
- 倒排索引 Reverted index
7 Hive:数据分析引擎
需要MySQL数据库。
数据仓库(数据库),基于Hadoop的数据分析引擎,支持SQL
- 支持SQL语句 –> 转成MapReduce执行
8 Pig:数据分析引擎
- 支持PigLatin语句 –> 转成MapReduce执行
9 HBase
-
NoSQL数据库
-
体系结构和安装配置
-
HBase的过滤器
-
基于HBase的MapReduce程序
10 Sqoop:数据交换
采集RDBMS(关系型数据库)中的数据
数据交换:RDBMS <—> Sqoop <—> HDFS
11 Flume:日志采集框架
日志采集:日志 —> Flume —> HDFS
12 HUE:Hadoop WEB管理工具
Hadoop的WEB管理工具。
13 Zookeeper
“数据库”,保存配置信息;
ZooInspector :Zookeeper图形工具
-
原理机制
-
功能:在Zookeeper的集群之间,会进行数据的自动同步
-
安装配置
14 Hadoop的集群和HA
-
NameNode联盟(Federation) —> Load Balance 负载均衡
-
基于Zookeeper实现Hadoop的HA(High Avaibility,高可用性) —> Fail Over 失败迁移
15 Storm:实时计算框架
-
什么是实时计算、离线计算?
-
什么是Storm?体系结构?
-
安装配置
-
开发程序:Topology(实时任务)
-
运行机制