[TOC]
MySQL 相关问题
1 索引类问题
参考文献
首先引入索引的目的是为了加快查询速度。
InnoDB 是 Mysql 的默认存储引擎,InnoDB 有两种索引:B+树索引和哈希索引,其中哈希索引是自适应性的,存储引擎会根据表的使用情况,自动创建哈希索引,不能人为的干涉。
四种数据结构在索引中的运用(顺序如下):
B树:二叉树,每个结点只存储一个关键字,等于则命中,小于走左结点,大于走右结点;
B-树:多路搜索树,每个结点存储M/2到M个关键字,非叶子结点存储指向关键字范围的子结点;所有关键字在整颗树中出现,且只出现一次,非叶子结点可以命中;
B+树:在B-树基础上,为叶子结点增加链表指针,所有关键字都在叶子结点中出现,非叶子结点作为叶子结点的索引;B+树总是到叶子结点才命中;
B*树:在B+树基础上,为非叶子结点也增加链表指针(指向兄弟结点),将结点的最低利用率从1/2提高到2/3;
聚簇索引和非聚簇索引表分布的差异如下:
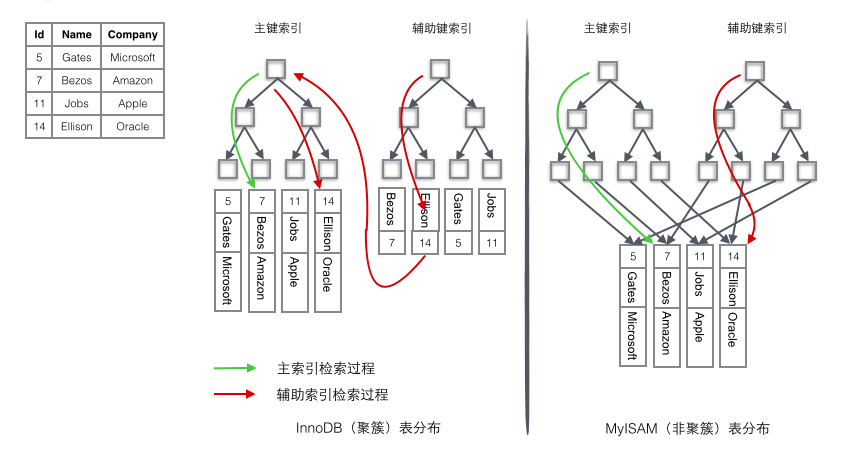
1.1 InnoDB 引擎中,给区分度低的字段加索引?
不能。
- 走区分度低的辅助键索引后再走主键索引,重复率非常高。
- 维护索引的代价高;索引越多,事务越大,代价越高;对表的插入和索引字段的修改越慢(内部封装了索引的事务)。
1.2 建立索引的原则
参考文献
-
最左前缀匹配原则,MySQL 会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配。如 a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
-
= 和 in 可以乱序。如 a = 1and b = 2 and c = 3 建立 (a,b,c) 索引可以任意顺序,MySQL 的查询优化器会优化成索引可以识别的形式。
-
尽量选择区分度高的列作为索引, 区分度的公式是 count(distinct col) / count(*),表示字段不重复的比例,比例越大扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就是0。那可能有人会问,这个比例有什么经验值吗?使用场景不同,这个值也很难确定,一般需要join的字段我们都要求是0.1以上,即平均1条扫描10条记录。 -
索引列不能参与计算。如 from_unixtime(create_time) = ‘2015-08-14’ 就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成create_time = unix_timestamp(‘2015-08-14’)。
-
尽量的扩展索引,不要新建索引。如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。
-
在order by或者group by子句中,如果想通过索引来进行排序,所建索引列的顺序必须与order by或者group by子句的
顺序一致,并且所有列的排序方向(倒序或者正序)都一样;如果查询关联多张表,则只有order by子句引用的字段全部来自第一张表时,才能利用索引来排序;order by或者group by语句与查询型语句的限制是一样的: 需要满足索引的最左前缀原则,否则mysql就要执行排序操作,无法利用索引来排序;(有一种情况order by或者group by子句可以不满足最左前缀原则,就是其前导为常量的时候,如果where或者join对这些列指定了常量,就可以弥补索引的不足)。
2 MySQL 的主从复制
参考文献
2.1 主从复制原理
主:log dump 线程,记录所有改变数据库数据的 INSERT, UPDATE, DELETE, CREATE, GRANT 等语句(不包含 SELECT),放进 master 上的 Binary log 中。
从:IO 线程,在使用 start slave 之后,负责从 master 上拉取 binlog 内容,放进自己的 Relay log 中。
从:SQL执行线程,执行 Relay log 中的语句。
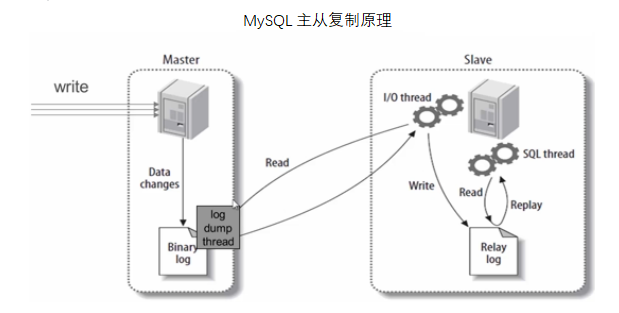
2.2 主从复制延迟的原因及解决方案
-
一个主库的从库太多,导致复制延迟
建议从库数量3-5个为宜,要复制的从节点数量过多,会导致复制延迟
-
从库硬件比主库差,导致复制延迟
查看master和slave的系统配置,可能会因为机器配置问题,包括磁盘IO、CPU、内存等各方面因素造成复制的延迟,一般发生在高并发大数据量的写入场景。
-
慢SQL语句过多
假如一条SQL语句执行时间是20秒,那么执行完毕到从库上能查到数据也至少是20秒,可以修改后分多次写入,通过查看慢查询日志或show full processlist命令找出执行时间长的查询语句或者大的事务。
-
主从复制设计问题
主从复制单线程,如果主库写并发太大,来不及传送到从库就会导致延迟。更高版本的mysql可以支持多线程复制,门户网站则会自己开发多线程同步功能。
-
主从库之间网络延迟
主从库的网卡,网线,连接的交换机等网络设备都可能成为复制的瓶颈,导致复制延迟,另外,跨公网主从复制很容易导致主从复制延迟。
-
主库读写压力大,导致复制延迟
主库硬件要搞好一点,架构的前端要加buffer。
3 数据库隔离级别
参考文献
数据库事务的隔离级别有4个,由低到高依次为 Read uncommitted、Read committed、Repeatable read、Serializable,这四个级别可以逐个解决脏读、不可重复读、幻读这几类问题。
3.1 ISOLATION_READ_UNCOMMITTED
-
事务最低的隔离级别。
-
所有事务都可以看到其他未提交事务的执行结果。
-
这种隔离级别会产生脏读,不可重复读和幻像读。
当A事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中,此时,B事务也访问这个数据,并使用了这个数据,这个数据是
脏数据。
3.2 ISOLATION_READ_COMMITTED
-
大多数数据库系统的默认隔离级别(但不是MySQL默认的)。
-
保证一个事务修改的数据提交后才能被另外一个事务读取。
-
这种隔离级别出现
不可重复读(Nonrepeatable Read)A事务两次或多次读同一数据,而B事务在这个过程中修改了数据,导致A事务两次读取的数据不一致,即不可重复读。
3.3 ISOLATION_REPEATABLE_READ
-
这是MySQL的默认事务隔离级别
-
这种事务隔离级别可以防止脏读,不可重复读。但是可能出现
幻像读A事务对全表数据进行操作,同时,B事务像表中插入了一行新数据,之后,A事务发现表中有未修改的数据行,即幻读。
-
InnoDB和Falcon存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了该问题。
3.4 ISOLATION_SERIALIZABLE
- 最高的隔离级别,花费最高代价,最可靠。
- 它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。
- 可能导致大量的超时现象和锁竞争。